
In recent years, non-relational DBMSs have reemerged with proponents’ claiming advantages in scalability and simplicity. Many of these DBMSs now exist targeted towards a variety of usage scenarios. They are popularly referred to as NoSQL databases. This article looks at how Node.js works with two popular NoSQL databases – Redis and MongoDB – and also Mongoose, a popular API that abstracts access to MongoDB.
Authors: Mike Cantelon and TJ Holowaychuk
This article is based on “Node.js in Action“, to be published in April 2012. It is being reproduced here by permission from Manning Publications. Manning early access books and ebooks are sold exclusively through Manning. Visit the book’s page for more information.
In the early days of the database world, non-relational databases were the norm. Relational databases, however, slowly gained popularity and became the mainstream choice for applications both on and off the web. In recent years, however, non-relational database management systems (DBMSs) have reemerged with proponents’ claiming advantages in scalability and simplicity. Many of these DBMSs now exist targeted towards a variety of usage scenarios. They are popularly referred to as NoSQL databases, interpreted as “No SQL” or “Not Only SQL”. In this article, we’ll look at two popular NoSQL databases: Redis and MongoDB. We’ll also look at Mongoose, a popular API that abstracts access to MongoDB, adding a number of time-saving features. The setup and administration of Redis and MongoDB are a large topic, but instructions are available for Redis and MongoDB that should help you get up and running.
Redis
Redis is a data store well-suited for handling simple, relatively ephemeral data such as logs, votes, and messages. It provides a vocabulary of primitive, but useful, commands that work on a number of data structures. Most of the data structures supported by Redis will be familiar to developers because they are analogous to those frequently used in programming: hashes, lists, and key/value pairs (which are used like simple variables). Redis also supports a less familiar data structure called a set, which we’ll talk about further on.
While we won’t go into all of Redis’s commands in this article, we’ll run through a number of examples that will be useful for many applications. If you’re new to Redis and want to get an idea of its power before trying these examples, a great place to start is Simon Willison’s Redis Tutorial.
The most mature and actively developed Redis API module is Matt Ranney’s node_redis module. Install this module using the following npm command.
npm install redis
The following code establishes a connection to a Redis server, using the default TCP/IP port, running on the same host. The Redis client created has inherited EventEmitter behavior and emits an “error” event when the client has problems communicating with the Redis server. As shown below, you can define your own error-handling logic by adding a listener for the “error” event type.
var redis = require(‘redis’),
client = redis.createClient(6379, ‘127.0.0.1’);
client.on(‘error’, function (err) {
console.log(‘Error ‘ + err);
});
Once connected to Redis, your application can start manipulating data immediately using the object. The following example client code shows the storage and retrieval of a key/value pair:
client.set(‘color’, ‘red’, redis.print);
var keyValue = client.get(‘color’, function(err, value) {
if (err) throw err;
console.log(‘Got: ‘ + value);
});
Listing 1 shows the storage and retrieval of values in a slightly more complicated data structure: the hash. The hset Redis command sets a hash element, identified by a key, to a value. The hkeys Redis command lists the keys of each element in a hash.
Listing 1 Storing data in elements of a Redis hash
client.hset(‘camping’, ‘shelter’, ‘2-person tent’, redis.print); #1
client.hset(‘camping’, ‘cooking’, ‘campstove’, redis.print);
client.hget(‘camping’, ‘cooking’, function(err, value) { #2
console.log(‘Will be cooking with: ‘ + value);
});
client.hkeys(‘camping’, function(err, keys) { #3
if (err) throw err;
keys.forEach(function(key, i) {
console.log(‘ ‘ + key);
});
});
#1 Sets hash elements
#2 Gets “cooking” element’s values
#3 Gets hash keys
Another data structure supported is the list. A Redis list can theoretically hold over 4 billion elements, memory permitting. The following code shows the storage and retrieval of values in a list. The lpush Redis command adds a value to a list.
The lrange Redis command retrieves a range of list items using a start and end argument. The “-1” end argument in code below signifies the last item of the list, hence this use of lrange will retrieve all list items.
client.lpush(‘tasks’, ‘Paint the bikeshed red.’, redis.print);
client.lpush(‘tasks’, ‘Paint the bikeshed green.’, redis.print);
client.lrange(‘tasks’, 0, -1, function(err, items) {
if (err) throw err;
items.forEach(function(item, i) {
console.log(‘ ‘ + item);
});
});
While lists, which are similar conceptually to arrays in many programming languages, provide a familiar way to manipulate data, one downside is retrieval performance. As the list grows in length, retrieval becomes slower—O(n) in big O notation.
Big O Notation
Big O Notation is a way of categorizing algorithms, in computer science, by performance. Seeing an algorithm’s description in big O notation gives a quick idea of the performance ramifications of the algorithm’s use. For those new to big O, Rob Bell’s “Beginner’s Guide to Big O Notation” provides a great overview.
Sets are another type of Redis data structure with better retrieval performance. The time it takes to retrieve a set member is independent of the size of the set—O(1) in big O notation. Sets, however, must contain unique elements. If you try to store two identical values in a set, the second attempt to store it will be ignored. The following code illustrates the storage and retrieval of IP addresses. The sad Redis command attempts to add a value to the set and the smembers command returns stored values. In the example, we attempt to add the IP “204.10.37.96” twice, but when we display the set members, you can see that it has only been stored once.
client.sadd(‘ip_addresses’, ‘204.10.37.96’, redis.print);
client.sadd(‘ip_addresses’, ‘204.10.37.96’, redis.print);
client.sadd(‘ip_addresses’, ‘72.32.231.8’, redis.print);
client.smembers(‘ip_addresses’, function(err, members) {
if (err) throw err;
console.log(members);
});
Redis, it’s also worth noting, goes beyond the traditional role of datastore by providing channels. Channels are a data delivery mechanism, as shown conceptually in figure 1, that provides publish/subscribe functionality, useful for chat and gaming applications.
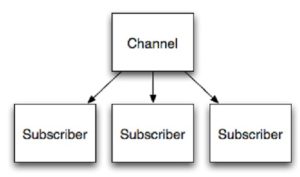
Figure 1 – Redis channels provide an easy solution to a frequent data delivery scenario.
A Redis client can both subscribe to and publish to any given channel. Subscribing to a channel means you get any message sent by others to the channel. Publishing a message to a channel sends the message to everyone else on that channel.
When you’re deploying a Node.js application to production that uses the node-redis API, you may want to consider using Pieter Noordhuis’s hiredis module. Using this module will speed up Redis performance significantly because it leverages the official hiredis C library. node-redis will automatically use hiredis, if installed, instead of its Javascript implementation. Install hiredis using the following npm command.
npm install hiredis
Note that because the hiredis library is compiled from C code, and Node’s internal APIs change occasionally, you may have to recompile hiredis when upgrading Node.js. Rebuild hiredis using the following npm command.
npm rebuild hiredis
Now that we’ve looked at Redis, which excels at high-performance handling of data primitives, let’s look at a more generally useful database: MongoDB.
MongoDB
MongoDB is a general-purpose non-relational database. It’s used for the same sort of applications as a relational database management system (RDBMS) and is well regarded for its performance capabilities. It stores data in RAM before writing so it’s a good choice if you wish to sacrifice reliability for speed. If reliability or availability is a concern, MongoDB has powerful replication features you can harness.
A MongoDB database stores documents in collections. Documents in a collection, as shown in figure 2, need not share the same schema: each document could conceivably have a different schema. This makes MongoDB much more flexible than conventional RDBMSs as you don’t have to worry about predefining schema.
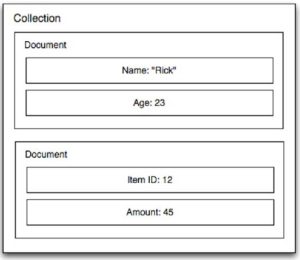
Figure 2 – If you use MongoDB to store data for your Node application, then each item in your MongoDB collection can have a completely different schema.
The most mature actively maintained MongoDB API module is Christian Amor Kvalheim’s node-mongodb-native. Install this module using the following npm command.
npm install mongodb
After installing node-mongodb-native and running your MongoDB server, use the following to establish a database server connection.
var mongodb = require(‘mongodb’)
, server = new mongodb.Server(‘127.0.0.1’, 27017, {});
var client = new mongodb.Db(‘mtest’, server);
Listing 2 shows how you can access a collection once the database connection is open.
Listing 2 Connecting to a MongoDB collection
client.open(function(err) {
client.collection(‘test_insert’, function(err, collection) {
if (err) throw err;
console.log(‘We are now able to perform queries.’); #1
});
});
#1 Puts MongoDB query code here
If, at any time after completing your database operations, you want to close your MongoDB connection, simply execute client.close().
The code below inserts a document in a collection and prints its unique document ID.
collection.insert({a: 2}, {safe: true}, function(err, documents) {
if (err) throw err;
console.log(‘Document ID is: ‘ + documents[0]._id);
});
Document IDs may be used to update data. Listing 3 shows how to update a document using its ID.
Listing 3 Updating a MongoDB document
var _id = new client.bson_serializer
.ObjectID(‘4e650d344ac74b5a01000001’);
collection.update(
{_id: _id},
{$set: {a: 3}},
{safe: true},
function(err) {
if (err) throw err;
}
);
You’ll notice in each of the previous examples that the option {safe: true} is specified. This indicates that you want the database operation to complete before the callback is executed. If your callback logic is in any way dependent on the database operation being complete, you’ll want to use this option. If your callback logic isn’t dependent, then you can get away with using {} instead.
Searching for documents in MongoDB is done using the find method. The example below shows logic that will display all items in a collection.
collection.find({a: 2}).toArray(function(err, results) {
if (err) throw err;
console.log(results);
});
Want to delete something? You can delete a record by its internal ID (or any other criteria) using code similar to the following.
var _id = new client
.bson_serializer
.ObjectID(‘4e6513f0730d319501000001’);
collection.remove({_id: _id}, {safe: true}, function(err) {
if (err) throw err;
});
While MongoDB is a powerful database and node-mongodb-native offers high-performance access to it, you may want to use an API that abstracts database access, handling the details for you in the background, so you can develop faster and have to maintain less lines of code. The most popular of these APIs is called Mongoose.
Mongoose
LearnBoost’s Mongoose is a Node module that makes using MongoDB painless. Mongoose models (in model-view-controller parlance) provide an interface to MongoDB collections as well as additional useful functionality such as schema hierarchy, middleware, and validation. Schema hierarchy allows the association of one model with another, enabling, for example, a blog post to contain associated comments. Middleware allows the transformation of data or the triggering of logic during model data operations, making possible things like the automatic pruning of child data when a parent is removed. Mongoose’s validation support lets you determine what data is acceptable at the schema level rather than having to deal with it manually. While we’ll focus solely on the basic use of Mongoose as a data store, if you decide to use Mongoose in your application, you’ll definitely benefit from reading its online documentation and learning all it has to offer.
Install Mongoose via npm using the following command.
npm install mongoose
Once you’ve installed Mongoose and have started your MongoDB server, the following example code will establish a MongoDB connection, in this case, to a database called tasks.
var mongoose = require(‘mongoose’)
, db = mongoose.connect(‘mongodb://localhost/tasks’);
If, at any time in your application, you wish to terminate your Mongoose-created connection, the following code will close it.
mongoose.disconnect();
When managing data using Mongoose, you’ll need to register a schema. The following code shows the registration of a schema for tasks.
var Schema = mongoose.Schema;
var Tasks = new Schema({
project: String,
description: String
});
mongoose.model(‘Task’, Tasks);
Once a schema is registered, you can access it and put Mongoose to work. The following code shows how to add a task using the appropriate model.
var Task = mongoose.model(‘Task’);
var task = new Task();
task.project = ‘Bikeshed’;
task.description = ‘Paint the bikeshed red.’;
task.save(function(err) {
if (err) throw err;
console.log(‘Task saved.’);
});
Searching with Mongoose is similarly easy. The task model’s find method allows us to find all or select documents using a JavaScript object to specify our filtering criteria. The following example code searches for tasks associated with a specific project and outputs each task’s unique ID and description.
var Task = mongoose.model(‘Task’);
Task.find({‘project’: ‘Bikeshed’}).each(function(err, task) {
if (task != null) {
console.log(‘ID:’ + task._id);
console.log(task.description);
}
});
Although it’s possible to use a model’s find method to zero in on a document that you can subsequently change and save, Mongoose models also have an update method expressly for this purpose. Listing 4 shows how you can update a document using Mongoose.
Listing 4 Updating a document using Mongoose
var Task = mongoose.model(‘Task’);
Task.update(
{_id: ‘4e65b793d0cf5ca508000001’}, #1
{description: ‘Paint the bikeshed green.’},
{multi: false}, #2
function(err, rows_updated) {
if (err) throw err;
console.log(‘Updated.’);
}
);
#1 Update using internal ID
#2 Only update one document
Using Mongoose, it’s easy to remove a document once you’ve retrieved it. You can retrieve and remove a document using its internal ID (or any other criteria if you use the find method instead of findById) using code similar to the following.
var Task = mongoose.model(‘Task’);
Task.findById(‘4e65b3dce1592f7d08000001’, function(err, task) {
task.remove();
});
There is much to explore in Mongoose. It’s a great all-around tool that enables you to pair the flexibility and performance of MongoDB with the ease of use traditionally associated with relational database management systems.
Summary
Don’t be afraid to use more than one type of storage mechanism in an application. If you were building a content management system, for example, you might store web application configuration options using SQLite, stories using MongoDB, and user-contributed story ranking data using Redis. How you handle persistence is limited only by your imagination.
This article was originally published on cloudcomputingdevelopment.net